Sometime you read a paper and you keep thinking about it. That’s what happened to me with the latest work from Xin Jin’s lab (yes, I am in awe of this work) in which they show that there exists a hierarchical organization of learned action sequences .
First of all, what’s an action sequence and what’s the problem? Let’s assume I need to do ABCD to obtain a given reward (i.e. [toss the ball (A)], [bring the racket shoulder height (B)], [extend the arm(C)], [hit the ball(D)] -> become a millionaire (reward)). How do I create a mental representation of this sequence so to be able to perform it? I might generate a representation of the linear sequence of action-tokens (“A”->”B’”->”C”->”D’”) that leads to the reward (where a token would be a minimal action element that constitutes a finite action, such as in our example [toss the ball] ). Alternatively, my mental representation could entail a clustering of action-tokens into meaningful “action-set”, resulting from the Merge of multiple tokens, i.e. “{A,B}” such as [toss the ball and bring the racket shoulder height] -> “{C,D}” [extend the arm and hit the ball]. In other words, in my mental construction, either single action-tokens bear meaning or it is only the action-set such as “{A,B}” that does (we’ll discuss later on what meaning in the action realm might mean, pun not intended).
Xin Jin and collaborators, with a series of elegant experiments show that the latter is true, at least from a basal-ganglia-centric point of view. Very briefly (as for once I don’t intend to discuss the experimental part in great detail so to have time to venture a bit outside the main scope of the work), what they did was to train mice to perform a defined action sequence, consisting of an ordered series of lever presses, in order to obtain a reward (the accent here is on ordered). Such an action sequence could be composed, for instance, of two Left lever presses followed by two Right ones (LLRR, see figure below). They then manipulated the activity of basal ganglia neurons of either the direct or indirect pathway and assesed how this impacted on the ongoing action sequence. I will argue that manipulating these pathways and test what happens to the individual action-tokens of the action-sequence is a way to ask the mouse to define what are the foundamental elements of such a series (i.e are they the action-tokens or the action-set?, see also the concept of “Chunking of action repertoires” in Graybiel, 1998), as only such elements will be affected by the manipulation (if you don’t agree with this, you’ll disagree with all that follows).
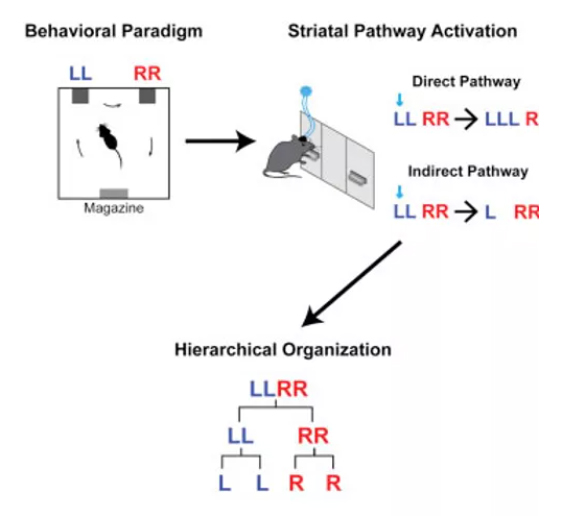
What does this imply in broader terms? [Disclaimer, what follows is on me as the authors, with good reasons, don’t venture in the nonsense I am about to embark on].
Albeit not explicitly claimed or discussed by the authors, reading this work it’s hard to resist to the allure of the idea of the existence of a syntactic organization of actions. There is no doubt that the hierarchical organization of learned action sequence uncovered by Xin Jin and collaborators bears striking resemblance with Chomsky’s hierarchical structure of language (Chomsky, 1957, see figure below) [hence half of the title of this post… the other half is there only because I love Umberto Eco’s essay on Semiotics].
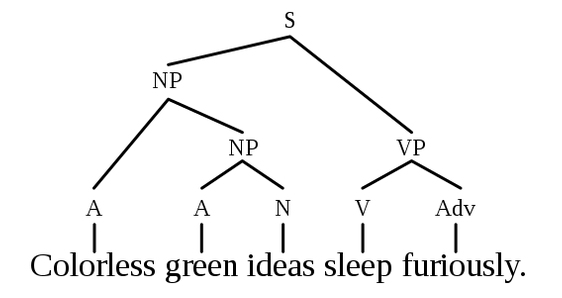
Now, I know that I am not being very original as such an analogy has already been suggested multiple times in the past (Pulvermuller and Fadiga 2010; or think of the “high order vocabulary” in Rizzolatti et al., 1988), but, as correctly pointed out previously (Moro, 2014), “is this analogy between language and actions true, or, at least, useful?”.
Two main criticisms are usually associated with the analogy between language and actions (indeed more than two… but for brevity let’s focus on the key ones): 1) the lack of action equivalents of ‘functional words’ such as those containing logical instructions (i.e. “if”, “then”, “not”); 2) The existence (or lack thereof) of principles governing parsing (the assignment of a syntactic structure to recursively merged lexical items) of an action sequence (action-phrase).
With respect to the first, it has always been my impression that this, really, is a non-problem. In the action realm, logical instructions are implicit in the motor sequence and reflect the learning paradigm related to the specific sequence. For example, in the task devised by Xin Jin and colleagues, mice have been trained to do 2x Left ever presses (“LL”) followed by 2x Right lever presses (“RR”) in order to obtain a reward. Now, from perspective of the animal, such a sequence can be algorithmically implemented as: “if” I [press the left lever twice] “then” [[press right lever twice] “and” [“do not” press left again]] I’ll be rewarded. I guess you’ll agree that, in such an action-lexicon, functional words (“if”, “then”, “not”) are implicit in the learned motor sequence. Indeed, one could even argue that the ordered sequence of the actions taken (and of all of those not taken) is the physical implementation of such logical operators – and that’s it for point one.
With respect to the second criticism the situation is a bit more complex, but this is where in a final, brilliant and somehow understated experiment, Xin Jin’s work shines. In linguistics, the process of Merge is one in which lexical items are combined, potentially ad infinitum. However, possibly due to limits to memory capacity or time pressure on decoding, strategies to simplify the identification of underlying syntactic structure seem necessary. One of such strategies consists in parsing by “minimal attachment” principles (the parser builds the simplest syntactic structure possible, the one with few nodes). “Marco spoke to Letizia and Laura replied that…”, in this example of Merge the reader has to understand who is the subject of spoke and replied. It’s clear that the process of parsing is intimately linked to/derived by the nature of language itself and that by parsing a sentence we reveal something about the logic of how it is generated. By reflection, one could say that if we understand how action-phrases are parsed we’ll understand something about how they are generated.
The Frazier’s serial modular model of parsing (the so called garden path model) postulates that one first defines the structure of the sentence by principles of minimal attachment and late closure (the principle by which incoming words tend to be associated with the phrase currently being processed), and that only at a later point one refines it according to the semantic meaning of its components (I ask what it actually means).
At the other end of the spectrum, there is the idea that, in order to correctly parse a sentence, a contextual and semantic understanding must take place first.
So, do Xin Jin and colleague tell us something about whether modular or semantic parsing occur at all in the action realm? I’d say yes, to some extent at least, but this is where I am stretching my argument very thin. In the action-phrase LLRR, principle of Locality might lead to clustering “LL” together and hence, “RR”. But what if I add an extra “L” and an extra “R”; how do I parse this new action-phrase then? This is what Xin Jin and collaborators did by training mice on an [LLLRRR] task. It turns out that mice now see “LLL” and “RRR” as action-sets (always in a basal-ganglia-centric point of view), as opposed to “LL” “LR” “RR” as it might have emerged from Locality principles alone. In other words, it seems to me, that basal ganglia do care about the semantic of the action and that such semantic is assigned, in the action realm, on the basis of learned outcomes; hereby, in the latter contingency (LLLRRR), “LL” ceases having a semantic meaning as no learned outcome is linked to it, while “LLL” gains a semantic meaning by means of the reward linked to its implementation.
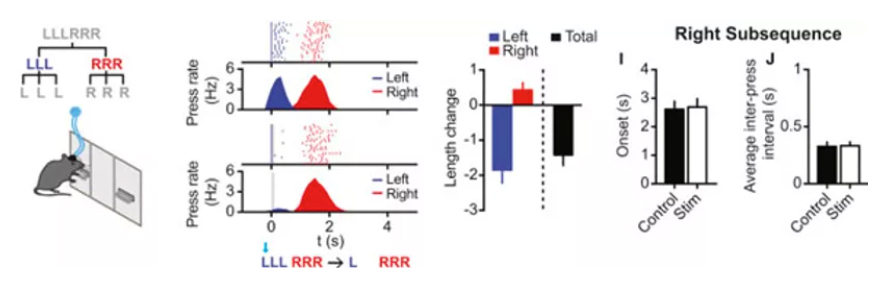
Now, I need to stress that experiments were not designed with a linguistic angle in mind (I guess) and hence they are not immediately suited for making these points, yet I still think that it’s interesting (at least fun) to think about it in these terms.
Hence, with respect to this action-language analogy, three things emerge from this study, the first of which very clearly, while the other two less so: firstly, action sequences (action-phrases) are hierarchically organised (which is indeed the main claim of the authors); secondly, parsing action-phrases (or generating/crystallising them) requires some element of semantic understanding; finally, semantic understanding in the context of actions would be linked to some reward probability function (if a given action-set impacts on the statistics of the world, that would give the set a meaning). Clearly the last two points are far from being proven and new experiments could be designed, starting from the current experimental design, in order to address them more directly.
In summary, it’s probably early to say whether the analogy between language and action is true, however, going back to Moro’s question, I believe that it might be indeed a very useful one.