Chomsky and the platypus
Sometime you read a paper and you keep thinking about it. That’s what happened to me with the latest work from Xin Jin’s lab (yes, I am in awe of this work) in which they show that there exists a hierarchical organization of learned action sequences . First of all, what’s an action sequence and what’s the problem? Let’s assume I need to do ABCD to obtain a given reward (i.e. [toss the ball (A)], [bring the racket shoulder height (B)], [extend the arm(C)], [hit the ball(D)] -> become a millionaire (reward)). How do I create a mental representation of this sequence so to be able to perform it? I might…

Owning your mistakes
With her distinctive style Eve Marder talks about mistakes in science. http://elifesciences.org/content/4/e11628
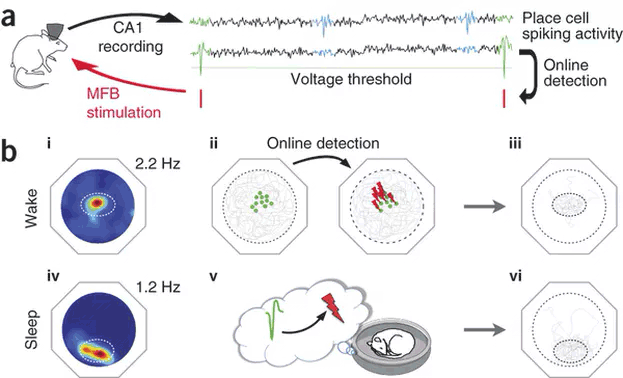
Causal role of place cells in navigation and spatial memory
An interesting work from the Benchenane’s lab reinforces the idea of the causal role of individual place cells in navigation and spatial memory. The experimental design makes use of live spike detection to associate a positive neural reward (by stimulating the medial forebrain bundle) following the spike of a clearly isolated individual place cell. Following the stimulation protocol either in awake or asleep mice, navigation is strongly biased towards the place field codified by the place cell used to trigger the reward. Full Article in Nature Neuroscience
Continue Reading Causal role of place cells in navigation and spatial memory

Cambridge Neuroscience 2015
On Friday the 20th of March we are please to host this year’s Cambridge Neuroscience seminar. For details on the program visit the Cambridge Neuroscience page.
Human-level control through deep reinforcement learning
https://youtu.be/xN1d3qHMIEQ Demis Hassabis and colleagues at DeepMind have published their work on Q-networks. The agent is capable of learning how to play a number of Atari games by receiving only pixels and score as ‘sensory input’. Its performance surpasses that of any professional human game tester. Link to the article
Continue Reading Human-level control through deep reinforcement learning